
Перевод статьи мы попросили сделать наших партнеров – бюро переводов и локализации Workogram.

Когда речь заходит об алгоритме действия новостной ленты, вспоминается множество теорий и мифов. Большинство людей понимают, что в работе есть определенный алгоритм, и многие знают какие-то факторы, влияющие на его функционирование (нравится ли вам сообщение, интересуетесь ли вы этим и т. д.). Но по-прежнему остается много других вопросов.
Мы публично делимся подробностями и особенностями новостной ленты. Но за кадром остается невероятно сложная и многоуровневая система машинного обучения ранжированию, которая обеспечивает работу новостной ленты. Мы делимся новыми деталями о том, как работает наша система ранжирования, рассказываем о сложностях построения системы персонализации контента для более чем 2 миллиардов человек и отображения актуального и значимого для них контента, каждый раз, когда они заходят на Facebook.
Что в этом сложного?
Во-первых, огромный объем. Более 2 миллиардов человек по всему миру пользуются Facebook. На каждого из них приходится более тысячи потенциальных публикаций (или постов, которые теоретически могут появиться в их ленте). Сейчас речь идет о триллионах публикаций всех людей в сети Facebook.
Обратите внимание, что для каждого пользователя Facebook существуют тысячи сигналов, которые необходимо оценить, чтобы определить, что может оказаться наиболее актуальным для этого человека. Это триллионы сообщений и тысячи сигналов – и нам нужно мгновенно предсказать, что каждый из этих людей захочет увидеть в своей ленте. Когда вы открываете Facebook, процесс происходит в фоновом режиме всего за секунду или около того, когда требуется загрузить вашу новостную ленту.
И как только все это заработает, ситуация может измениться. Нам следует учитывать возникновение новых моментов, такие как кликбейт и распространение недостоверной информации. Когда это происходит, нам нужно искать новые решения.
На самом деле система ранжирования – это не единственный алгоритм. Мы применяем многоуровневые модели машинного обучения и ранжирования для того, чтобы спрогнозировать наиболее релевантный и значимый для каждого пользователя контент. По мере того, как мы проходим каждый этап, система ранжирования сужает эти тысячи потенциальных публикаций до нескольких сотен, которые появляются в чьей-либо новостной ленте в определенный момент.
Как это работает?
Система определяет, какие посты появляются в вашей ленте новостей и в каком порядке, прогнозируя, что вас заинтересует. Эти прогнозы основываются на различных факторах: за чем и за кем вы следили, что вам понравилось, или с кем вы общались в последнее время и т. д.
Чтобы понять, как это работает на практике, давайте на примере рассмотрим, что происходит с пользователем, который входит в Facebook. Назовём его Хуаном.
После вчерашнего входа Хуана в систему его друг Вэй разместил фотографию своего кокер-спаниеля. А подруга Саанви выложила видео с утренней пробежки. На его любимой странице опубликовали интересную статью о том, как лучше рассмотреть Млечный Путь ночью, в то время как его любимая кулинарная группа разместила 4 новых рецепта закваски.
Весь этот контент может заинтересовать Хуана, потому что он сам решил следить за определенными людьми или за страницами. Чтобы решить, что из этого должно появиться выше в новостной ленте Хуана, нам нужно предсказать, что для него важнее всего, какой контент имеет для него наибольшую ценность. С математической точки зрения мы должны определить объективную функцию для Хуана и выполнить однонаправленную оптимизацию.
Мы можем использовать характеристики публикации (к примеру, отметки на фото и время его размещения), чтобы предсказать, понравится ли она Хуану. Например, если Хуан часто реагирует на публикации Саанви (делится или комментирует), а её видео с пробежки появилось совсем недавно, то высока вероятность, что Хуану публикация понравится. Если ранее Хуан реагировал на видео больше, чем на фотографии, то интерес к фотографии Вэя с его кокер-спаниелем может быть довольно низким. В этом случае наш алгоритм ранжирования поставил бы видео с пробежки Саанви выше, чем фотографию собаки Вэя, потому что он прогнозирует более высокую вероятность того, что понравится Хуану.
Но лайки – это не единственный способ, которым люди выражают свои предпочтения на Facebook. Каждый день люди делятся статьями, которые им кажутся интересными, смотрят видео обычных людей или знаменитостей, за которыми они следят, или оставляют комментарии на публикациях своих друзей.
С математической точки зрения все усложняется, когда нам необходимо оптимизировать работу для достижения нескольких целей, составляющих нашу главную задачу: создать наиболее долгосрочную ценность для людей, показывая им контент, который является значимым и актуальным для них.
Различные модели машинного обучения дают Хуану множественные прогнозы: вероятность того, что он заинтересуется фотографией Вэя, видео Саанви, статьей о Млечном Пути или рецептами закваски. Каждая модель пытается ранжировать эти части контента для Хуана. Иногда они расходятся во мнениях – существует высокая вероятность того, что Хуану больше понравится видео с пробежки Саанви, чем статья Млечного Пути, но он скорее прокомментирует статью, чем видео.
Поэтому необходимо найти способ объединить эти различные прогнозы в один результат, оптимизированный для достижения нашей основной цели – долгосрочной ценности.
Как можно определить, представляет ли что-то долгосрочную ценность для человека?
Мы просто спрашиваем их. Например, опрашиваем людей, чтобы выяснить, насколько значимым для них оказалось общение с друзьями, стоила ли публикация потраченного времени. Так наша система сможет отобразить то, что, по словам людей, им нравится, что они считают значимым. Затем мы можем принять во внимание каждый прогноз для Хуана, основанный на действиях, которые, по мнению людей (через опросы), являются более значимыми и стоящими их времени.
От редакции. Курс «SMM-специалист» разработан для тех, кто хочет освоить новую профессию смм-специалиста. Вы сможете самостоятельно создать план публикаций контента, научитесь запускать рекламные кампании и анализировать их результаты. Приносить клиентам заявки и продажи из социальных сетей.
Пошаговая инструкция
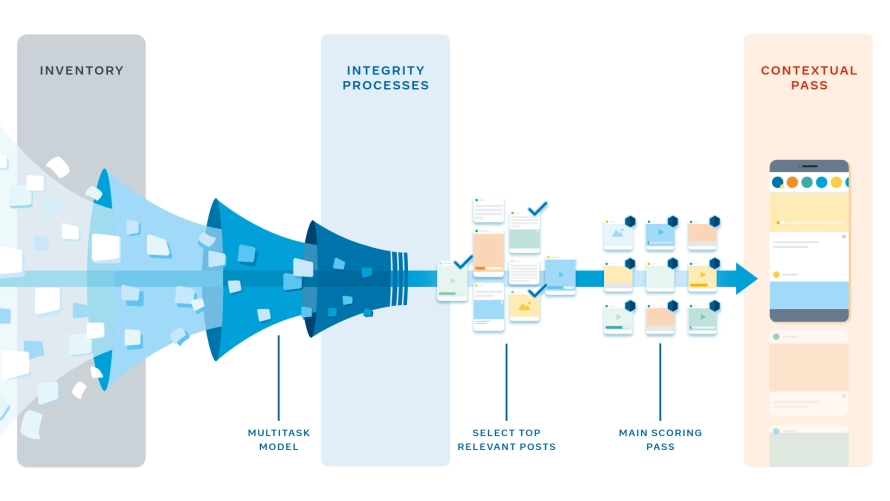
Чтобы ранжировать более тысячи публикаций на одного пользователя в день, для более 2 миллиардов человек в режиме реального времени, нам необходимо сделать этот процесс более эффективным. Мы осуществляем это поэтапно. Каждый этап стратегически так организован, чтобы ускорить процесс и ограничить количество необходимых вычислительных ресурсов.
Система собирает все потенциальные публикации, которые мы можем ранжировать для Хуана (фотография кокер-спаниеля, видео с пробежки и т. д.). Этот список включает в себя все публикации, которыми поделились с Хуаном друг, группа или страница, с которой он связан, и которые были сделаны с момента его последнего входа в систему и не были удалены.
Но как мы должны обрабатывать публикации, созданные до последнего входа Хуана в систему, которые он ещё не видел?
Для того чтобы убедиться, что незамеченные публикации были просмотрены, мы применяем логику непрочитанных бампингов: свежие посты, ранжированные для Хуана (но не замеченные им) в его предыдущих сессиях, добавляются в список приемлемых для этой сессии. Мы также применяем логику реакции на действия. То есть все публикации, которые Хуан уже видел и которые с тех пор вызвали интересную беседу между его друзьями, также добавляются в список приемлемых для этой сессии.
Далее система должна оценить каждый пост с учетом различных факторов, таких как тип поста, сходство с другими публикациями, и насколько этот пост соответствует тому, в чем Хуан обычно заинтересован. Чтобы подсчитать это для более 1000 публикаций, для каждого из миллиардов пользователей, и все в режиме реального времени, мы запускаем эти модели в работу параллельно для всех потенциальных историй на нескольких устройствах, которые называются «предикторами».
Прежде чем мы объединим все эти прогнозы в один результат, нужно учесть некоторые правила. Мы ждем, пока не получим эти первые прогнозы, чтобы сократить количество публикаций для ранжирования, и применяем их на нескольких этапах, чтобы сэкономить вычислительную мощность.
К каждому посту применяются определенные принципы целостности. Они предназначены для выяснения того, какие меры по определению целостности должны применяться к материалам, отобранным для ранжирования. На следующем этапе простая модель сокращает количество потенциальных публикаций примерно до 500 наиболее релевантных для Хуана. Ранжирование меньшего количества материала позволяет нам использовать более мощные нейросетевые модели на следующих этапах.
Далее следует основной этап отбора, на котором осуществляется большая часть персонализации. Здесь оценка каждой истории подсчитывается отдельно, а затем все 500 публикаций расставляются по порядку согласно полученным результатам. В некоторых случаях оценка за лайки может быть более высокой, чем за комментарии, так как некоторые люди любят выражать свои предпочтения больше через лайки, а не через комментарии. Любое действие, в котором человек редко принимает участие (например, прогноз по лайкам практически равен нулю), автоматически получает минимальную роль в рейтинге, так как прогнозируемое значение очень низкое.
И наконец, мы переходим к контекстуальному этапу, на котором добавляются такие функции, как правила разнообразия типов контента. Это необходимо для того, чтобы убедиться, что новостная лента Хуана имеет хорошее сочетание типов контента, и он не видит несколько видеопостов, один за другим.
Все эти шаги ранжирования происходят за отрезок времени, необходимый Хуану для открытия приложения Facebook. В течение нескольких секунд он получает результат новостной ленты, который может просматривать и получать от этого удовольствие.
Над статьей также работали: Мейхонг Ван, технический директор, Так Ян, директор по производству.



















Авторизуйтесь, чтобы оставлять комментарии