
Переклад статті ми попросили зробити наших партнерів – редакцію сайту Першого Кембриджського освітнього центру.
Причин не показувати окремі сторінки сайтів у пошуковій видачі може бути чимало. У цій статті ми обговоримо різні способи, які дозволяють приховувати веб-ресурси від пошукових систем.
Основні способи видалення сторінки з індексу пошукових систем:
- Теги noindex
- Файли robots.txt
- Видалення сторінок
- Інструмент видалення URL у Google Search Console
- Теги канонічності (rel=”canonical”)
Який контент не потрібен у Google?
Є кілька типів сторінок, які не варто індексувати та показувати у видачі Google та інших систем:
- Рекламні лендінги
- Сторінки подяки
- Адмін-сторінки
- Результати пошуку на сайті
Також сторінки в Google приховують внаслідок:
- дублювання сторінок – щоб інші версії одного й того самого контенту не з'являлись у пошуку;
- канібалізації ключових слів – коли однакові сторінки сайту конкурують між собою за пошукові запити;
- надмірної витрати краулінгового бюджету – коли Google витрачає занадто багато часу на пошук малокорисних сторінок замість індексації важливого контенту.
Як Google вибирає сторінки для результатів пошуку?
Перш ніж говорити про плюси та мінуси того чи іншого способу видалення сторінок з Google, не завадить коротко описати процес, за допомогою якого Google знаходить і ранжує сайти.
- Краулінг – це механізм, за допомогою якого Google підбирає новий контент, для чого задіюються програми-краулери або пошукові роботи. Google заходить на різні сторінки сайтів, переходить по внутрішніх посиланнях і так знаходить нові сторінки. Для кожного сайту краулінговий бюджет або обсяг задіяних ресурсів суворо обмежений.
- Індексація – як тільки Google знаходить потрібний контент, його копія зберігається у так званому індексі.
- Ранжування або порядок, в якому веб-сторінки розташовуються у результатах пошуку. Користувач вписує запит у Google. Пошукова система оцінює його, співставляє з тим, що вже є в індексі, та видає кращі з наявних результатів.
Google застосовує всілякі підрахунки та обчислення (алгоритми), щоб з'ясувати, які сторінки найбільш релевантні, та розміщує їх вище.
Як можна вплинути на результати пошуку Google?
Теги noindex
По суті, це вказівка Google не індексувати певні сторінки, тобто не показувати їх у результатах пошуку. Коли пошуковий робот в наступний раз просканує сторінку з цією директивою, він видалить її з індексу або, інакше кажучи, з результатів пошуку.
2 способи додати теги noindex:
- Додати їх до HTML-коду сторінки.
- Налаштувати повернення заголовка noindex у HTTP-відповіді.
Теги noindex, додані до HTML, виглядають приблизно так:

Теги Noindex у заголовку HTTP:
HTTP/... 200 OK
…
X-Robots-Tag: noindex
За допомогою CMS-систем, таких як WordPress, можна навіть без технічних знань додати теги noindex на сторінки.
Важливо пам'ятати, що пошуковому роботу необхідно просканувати сторінку, щоб виявити тег noindex і вилучити статтю з видачі.
Коли варто використовувати noindex. Цією опцією варто скористатися, якщо сторінки сайту виконують певну функцію, але при цьому ви не хочете, щоб вони з'являлись у Google.
Robots.txt
Robots.txt – це текстовий файл, який повідомляє пошуковим роботам, що потрібно робити, коли вони заходять на ваш сайт. З їхньою допомогою можна вказати пошуковій системі, які розділи сайту дозволено обробляти.
Ось приклад файлу robots.txt на сайті Nike:
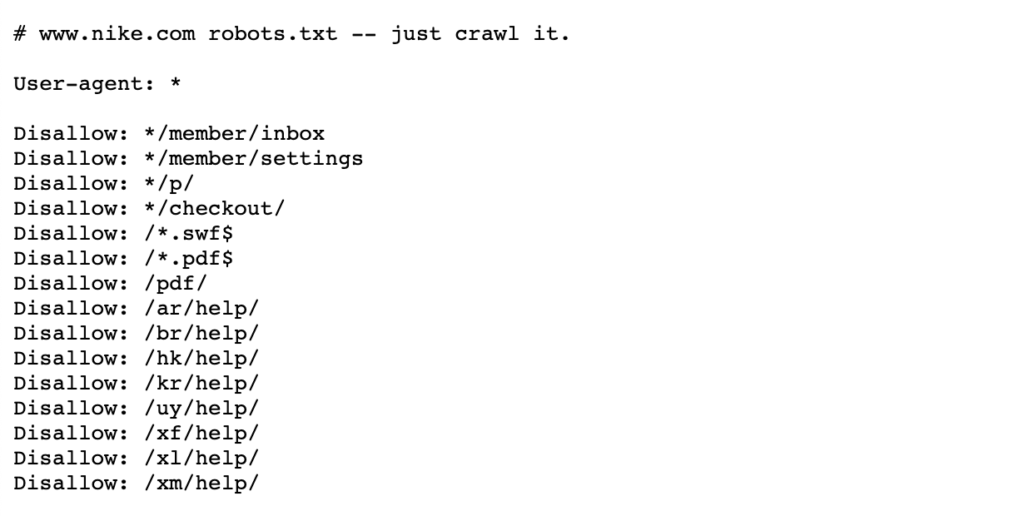
Якщо ви використовуєте robots.txt для блокування певних каталогів, таких як /admin/, це означає, що Googlebot або пошукові роботи інших систем навіть не будуть заходити на ці сторінки. Таким чином, краулінговий бюджет витрачатиметься на більш важливий контент.
Враховуйте, що блокуючи шлях до сторінки за допомогою файлів robots.txt, ви забороняєте зберігати сторінку, але при цьому те, що було збережено раніше, не видаляється і не змінюється. Якщо сторінка вже є в результатах пошуку, це означає, що Google її обробив і проіндексував.
Якщо потрібно видалити сторінку, блокування за допомогою robots.txt не допоможе. Для цього спочатку потрібно додати тег noindex, щоб вилучити статтю зі свого індексу. І тільки після того, як вона буде видалена, ви вже зможете заблокувати сторінку у файлі robots.txt.
Коли варто блокувати сторінки у robots.txt. Тоді, коли є певні шляхи до сторінок або об'ємні розділи сайту, які ви не хочете, щоб Google сканував.
Якщо одна сторінка або кілька вже з'являються у пошуку, спочатку знадобиться додати до них тег noindex і почекати, поки їх видалять з індексу, і лише потім застосовувати robots.txt.
Більше інформації – у довідці Google.
Видалення сторінки
Найпростіше рішення – видалити сторінку, створивши код відповіді 404 або 410. Обидва коди виконують одну й ту саму функцію. У результаті Google видалить сторінку з індексу під час її наступного сканування. За словами Джона Мюллера, код 410 може бути швидшим способом видалити сторінку.
З точки зору SEO, якщо сторінка корисна (наприклад, вона генерує трафік або зворотні посилання), тоді є сенс налаштувати переадресацію 301 на релевантну сторінку, щоб зберегти посилальну вагу сайту.
Якщо на сторінці є внутрішні посилання, а у вас немає підходящої сторінки, щоб зробити редирект 301, тоді ці внутрішні посилання потрібно видалити або замінити кодом відповіді 200.
Коли варто видаляти сторінки. Якщо сторінка вам не потрібна, якщо в ній мало цінності для посилального профілю, її можна прибрати без будь-яких небажаних наслідків. Якщо це корисна сторінка (наприклад, потрібна користувачам або цінна з точки зору SEO), тоді її варто відзначити тегом noindex або налаштувати редирект 301 на релевантну сторінку.
Інструмент видалення URL у Google Search Console
Інструмент видалення в Search Console тимчасово блокує показ сторінок у видачі. Це тимчасове і разом з тим досить ефективне рішення, щоб швидко прибрати сторінку з Google.
Якщо потрібно назавжди видалити сторінку, Google рекомендує використовувати 404 або 410, блокувати доступ до контенту за допомогою пароля або додавати на сторінки директиву noindex.
Коли варто використовувати інструмент видалення URL. Коли потрібно швидко видалити сторінку з видачі. Якщо бажаєте остаточно вилучити сторінку, використовуйте директиву noindex або коди відповіді 404 чи 410.
Детальніше – у довідці Google.
Канонічні теги
Канонічний тег – це фрагмент коду HTML, який розташовується в елементі
сторінки та визначає основну версію сторінок зі схожим або однаковим контентом. Теги канонічності допомагають усунути проблеми, пов'язані з дублюванням контенту.Ось так може виглядати цей тег:

«Канонізуючи» сторінку таким чином, ви вказуєте, яка сторінка повинна бути основною, тобто яку сторінку потрібно індексувати.
На відміну від тегів noindex, які, по суті, служать вказівками для Google, канонічні теги – це тільки підказки, які Google може проігнорувати. Іншими словами, Google зауважує тег канонічності, а потім вже робить висновок, показувати сторінку у видачі чи ні.
Коли потрібно використовувати тег канонічності. Коли є кілька дублікатів або схожих ранжованих сторінок. Ще це допоможе зосередити посилальну вагу на одній сторінці та не розподіляти її між декількома.
Найбільш наочний приклад використання канонічних тегів – параметризовані адреси. Пошукові роботи сканують URL-адреси, а не власне сторінки. Наприклад, у інтернет-магазинів один і той самий вміст може розташовуватися на різних URL. У такому випадку тег канонічності підкаже Google, яка версія сторінки основна.

Ось приклад використання канонічних тегів
І на закінчення...
Існує кілька способів видалити або хоча б проконтролювати те, що з'являється в результатах пошуку. Головне – вибрати підходящий спосіб для кожного конкретного випадку.
Якщо ви хочете навчитися оптимізувати сайти і стати суперменом-сеошник, то можемо запропонувати курс SEO-спеціаліст». Після курсів проведете аудит сайту і створите стратегію просування. Навчіться аналізувати конкурентів, сформуєте семантичне ядро. Прогнозуючи результати просування, зможете оптимізувати бюджет. Привабливо? Записуйтесь!




















Авторизуйтесь , щоб залишати коментарі