
Содержание:
Что такое семантическое ядро сайта? Для чего нужно составлять этот пресловутый список, о котором seo-специалист говорит 80% времени? Как его разработать и что дальше делать с ключевиками? А когда уже есть готовое СЯ, нужно потом его пересматривать, дополнять, изменять? И как, вообще, выглядит «идеальный» список ключевых фраз?
Ответы на эти вопросы вы узнаете далее. Но начнем с определения.
Семантическое ядро — это упорядоченный набор слов, их морфологических форм и словосочетаний, которые наиболее точно характеризуют вид деятельности, товары или услуги, предлагаемые сайтом. Имеет центральное ключевое слово, как правило, высокочастотное. Все остальные ключевые слова в нём ранжируются по мере убывания частоты совместного использования с центральным запросом в общей коллекции документов. (Wiki)
Если определение вам показалось слишком непонятным или просто скучным, не переживайте. По ходу чтения все станет предельно ясным. Поведаю, как можно подобрать семантическое ядро своей мечты. Расскажу, что с ним делать и как использовать. И все это при помощи инструментов, которые есть у каждого человека: голова и две руки.
Прим. редактора: и, конечно, же Планировщика ключевых запросов Google Adwords и Яндекс Вордстат.
Итак, начнем.
Зачем нужна разработка семантического ядра

Чтобы вам было проще понять этот сложный процесс, приведу аналогию.
Представьте автомобиль любой марки, цвета, формы. Вообразите его обводы, комфортабельный салон, электронную начинку, где каждая деталь сделана именно для вашего удобства.

Автомобиль — это сайт в интернете
Вы лично или вместе со своими коллегами сделали его почти идеальным. И все бы классно, да только автомобиль не едет. Стоит на месте и никак не хочет двигаться. И кто-то восклицает: «Да он же не заправлен!». Оказывается, как все банально просто. Вы заправляете автомобиль (бензином, дизелем, электричеством) и он едет.
Точно так же работает сайт. Вы можете создать близкий к идеалу ресурс, но если он не будет «заправлен» СЯ, ничего не сдвинется с места. На сайт не будут приходить новые посетители и совершать целевые действия, а бизнес развиваться.
На практике сложно представить ресурс, который, вообще, не ранжируется в поисковых системах. В любом случае есть некое наполнение: название категорий, описание, контактные данные и т. п. Но это все можно сравнить с толканием машины. Ведь если толкать, она тоже будет ехать. Вот только вы будете снаружи, а не внутри.
Так что же надо, чтобы комфортно рулить в нужном направлении? Вникнуть в суть.
Работает все очень просто. Каждое ключевое слово в вашем собранном семантическом ядре — это еще одна дверца в вашу машину. Разумеется, есть и «ворота» (обычно их называют высокочастотными запросами). Но есть и куда более скромные, но не менее важные, «калиточки» (низкочастотные запросы). И вот каждая такая «дверь» ведет на ваш ресурс. Одни приводят много людей, другие — меньше.
Низкочастотные запросы в разы конверсионнее высокочастотных. То есть приносят больше финансовой выгоды для коммерческих проектов.
Отсюда вывод: КАЖДЫЙ ключевой запрос потенциально может привести к вам на сайт посетителя. Конечно, если он не придуман лично вами, а подобран с помощью Google Adwords или Yandex Wordstat.
Как собрать СЯ своей мечты
Правила сбора и работы с СЯ
Запомните эти несколько правил.
-
Никогда не придумывайте ключевые запросы.
-
Если вы начинаете придумывать, то смотрите правило номер один.
-
Анализируйте каждый ключевой запрос, чтобы понять его потенциал.
-
Не откидывайте ключевые фразы, какими бы мелкими они вам ни казались.
-
Помните, что семантическое ядро — это фундамент вашего ресурса, без которого все остановится.
Для сбора поисковых запросов рекомендую использовать первоисточники: Планировщик ключевых слов Google и Вордстат Яндекса.
Лайфхак для украинцев. Для подбора ключевых слов в Яндексе используйте VPN.
Но есть и специальные сервисы для создания ядра: Serpstat, SimilarWeb, Megaindex. Даже сервисы, работающие со ссылками, начали предоставлять информацию по ключевым словам. Например, Ahrefs. Выбирайте, тот что вам удобней.
Сбор ключевых слов
Теперь рассмотрим, как подобрать семантику.
Мой ответ: РУКАМИ! Если вы думаете, что существует сервис, который соберет идеальное СЯ по нажатию одной кнопки, тогда продолжайте так думать. И, может, вы когда-нибудь его сами и создадите. В нашей работе думать нужно всегда.
Прежде чем начать подбор ключевых слов, надо четко понимать тематику и аудиторию: для кого создан ваш ресурс и как потенциальный пользователь может вас найти. Люди разных возрастов, интересов, полов ищут по-разному. Проведите эксперимент на своих родных. Уверен, что вы будете удивлены.
И будьте проще. Работайте исходя из основного ключа. Если вам нужно собрать СЯ для «шариковой ручки», собирайте его для «ручки». Если под страницу «строительные услуги», выбирайте «строительство», для продажи «сусликов в тайге» берите слово «суслик». Тяните данные отовсюду: с любых сервисов, парсеров, БД в таблицу Гугла или Экселя.
Я работаю с Google таблицами, поэтому все дальнейшие формулы будут приводиться для Google Docs.
Один Google документ способен обрабатывать 2 миллиона ячеек. В большинстве случаев этого достаточно.
Хотя, в моей практике случались ситуации, когда возможностей Гугл таблиц было мало. Это когда я составлял полное СЯ по ключевику «автобус», причем с охватом России и Украины. Тогда приходилось использовать софт от Майкрософт.
В целом процесс сбора семантики несложный. Тем более сейчас так много разных статей и видео на эту тему. Смотрите, читайте, слушайте хоть целыми днями.
Почему я не привожу вам «идеальные» способы создания ядра? Да потому что сколько seo-специалистов, столько и способов. Каждый по-своему разделяет, группирует, использует свои алгоритмы. Я покажу вам один из способов, которым пользуюсь лично. Применять его в своей практике или нет — решать уже вам.
Важно! Подбирайте семантику под конкретную страницу, а не для ВСЕГО САЙТА сразу.
А теперь будем постигать науку на примере: быстро соберем нужное СЯ.
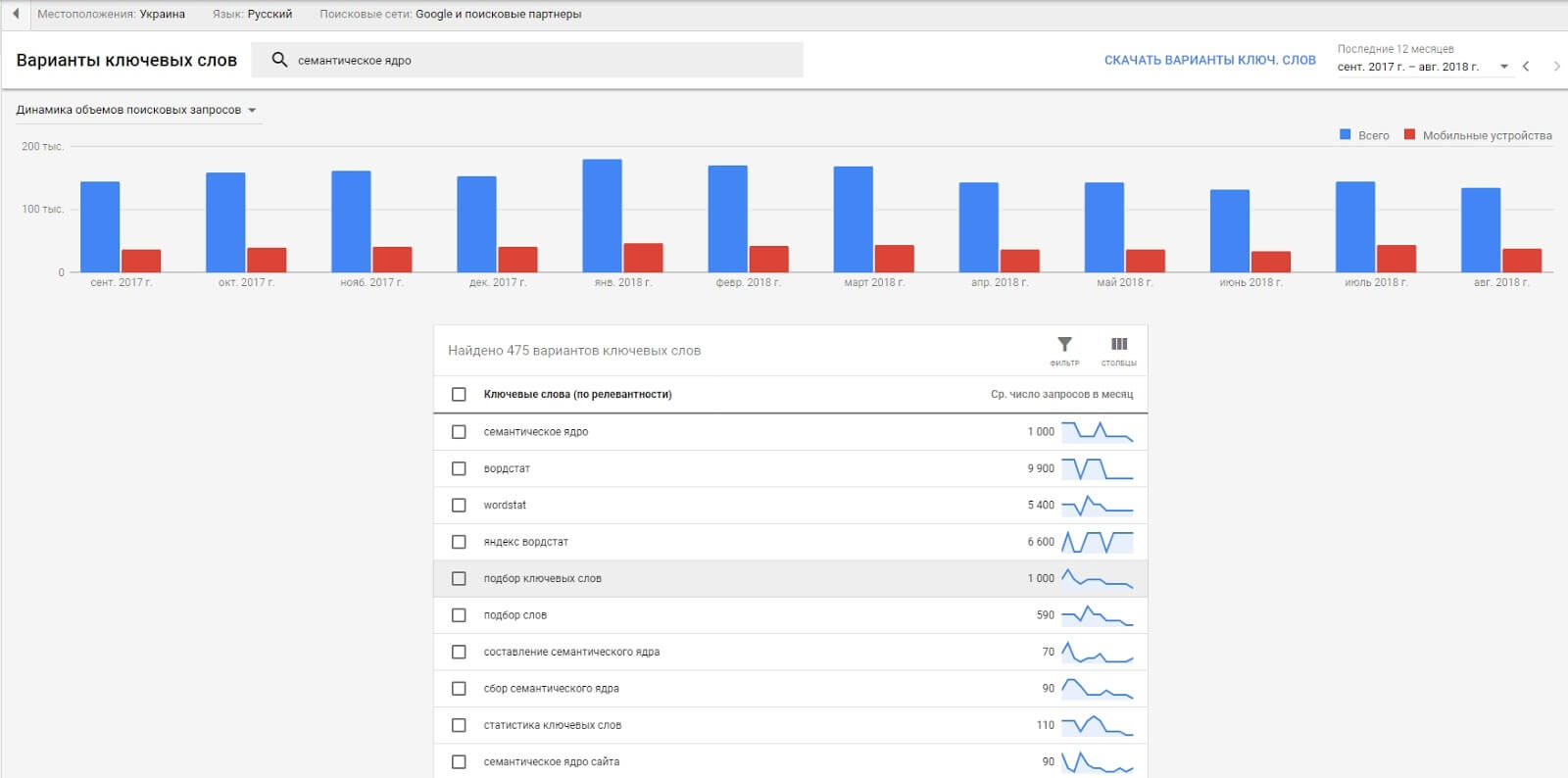
Интерфейс в Google Adwords выглядит так:
-
Заходите в Adwords. Нажимаете на «Инструменты» -> «Планировщик ключевых слов».

После загрузки страницы вы увидите следующее:
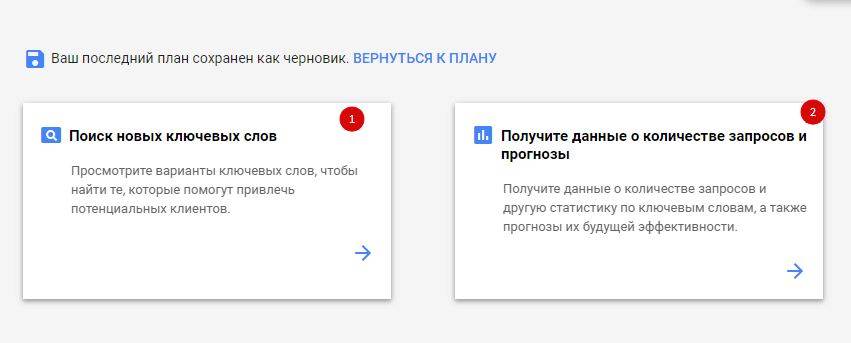
Первый раздел актуален для поиска новых слов. Второй — для получения данных о частотности ключевиков.
-
Выбираете «Поиск новых ключевых слов», вводите запрос, жмете «Начать» и ждете.
-
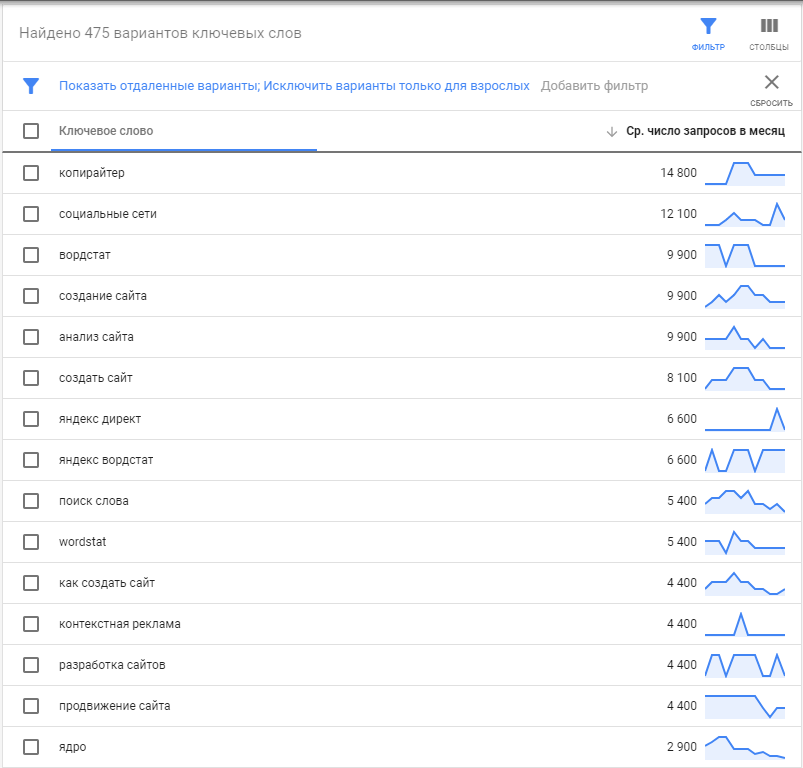
Получаете список ключевых запросов и частотность каждого ключа (внешний вид таблицы может отличаться от вашего, настраивается он по клику на «Столбцы» справа от синего значка «Фильтр»).
-
Можете прямо тут поиграться с фильтрами или выгрузить все данные, нажав на кнопку в правом верхнем углу окна браузера.

-
Ждете, пока идет анализ запросов. Загружаете файл с расширением .csv на свой ПК и можете приступать к работе. Я же для наглядности примера внес данные в эту таблицу. Можете ознакомиться.
В первую очередь работать предстоит с данными из первой и третьей колонки.
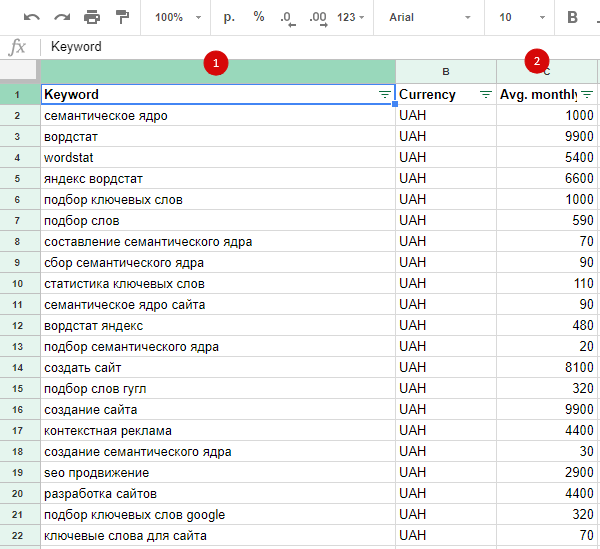
Далее, идете в Yandex.ua или Yandex.ru, чтобы провести анализ запросов и в этой поисковой сети.
-
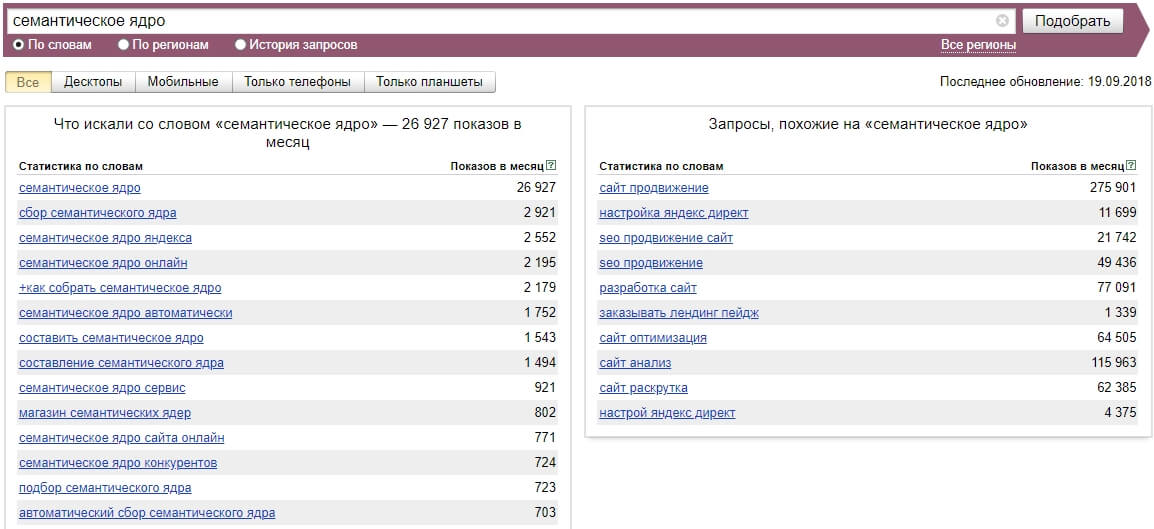
Вводите запрос и получаете данные.
-
Прежде всего вас интересует поле 1. Данные из него копируете в свой файлик. Я их перенесу в тот же файл, где данные из Google. Настройка 2 актуальна, если вам надо собрать ключевые запросы по определенному региону, чтобы понять как часто люди вводят его в поиск. Поле 3 отображает категории схожих фраз, что также будет полезным для подбора максимально полного СЯ.
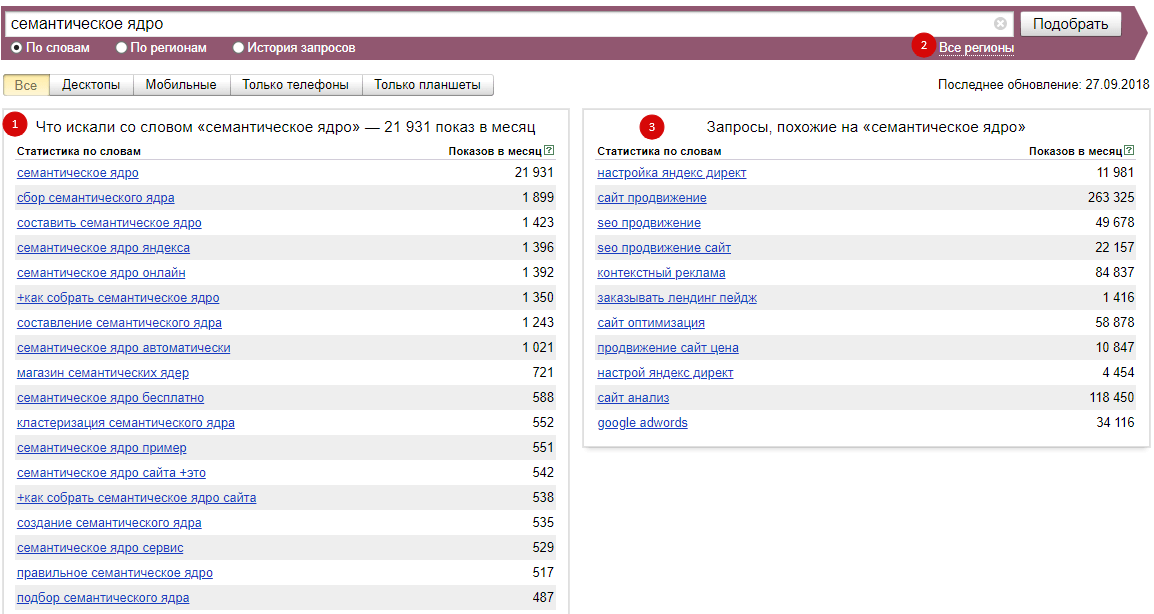
В данном примере получилось очень маленькое семантическое ядро. А после работы над ним оно станет еще меньше.
Как пользоваться разными сервисами лучше всего написано на сайтах самих сервисов. Так что изучите справки и определите для себя какой вам больше нравиться.
Не буду акцентировать внимание на том, что лучше всего указывать URL страницы, под которую собираются запросы. Так как может быть такой вариант, что нет еще сайта и самого урла. Хотя матерый seo-шник просто поставит шаблон урла в соседней колонке рядом с ключевым словом и будет нереально крут. Когда наступит время «Ч», обычная замена поможет все быстренько подправить.
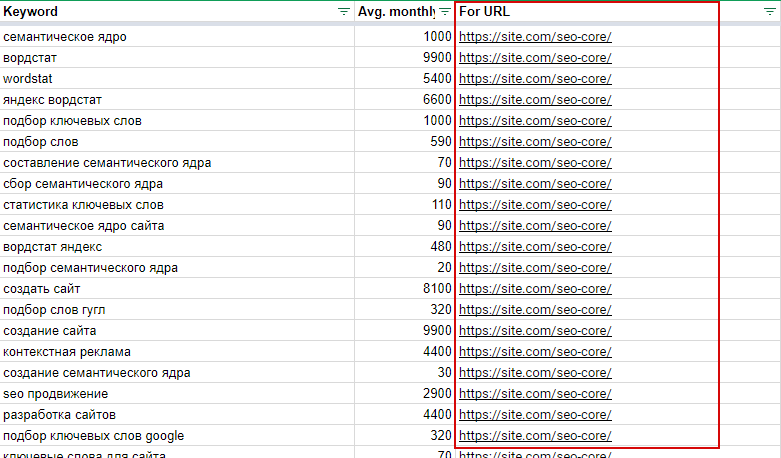
Вот мой вариант шаблона: https://site.com/[категория/товар/тег/блог/статья…]
Краткий чек-лист по сбору семантического ядра.
-
Регистрируете аккаунт Google и Яндекс.
-
Устанавливаете Оперу (В этом браузере уже есть встроенный VPN, без которого сбор СЯ из Яндекса будет проблематичным. В Chrome, Mozilla необходимо устанавливать дополнительный софт или плагины).
-
Заводите рекламную кампанию в Adwords.
-
Логинитеся в Яндекс под созданным аккаунтом.
-
Определяете основной ключ.
-
Вводите ключевик и переносите данные в таблицу.
Что делать дальше с ключевыми фразами
Кластеризация семантического ядра
Итак, собрано. Спустя дюжину бессонных ночей, сотни литров выпитого кофе вы достигли своей цели — красивые, ровные списки ключевых слов. Именно они приведут первого посетителя на ваш сайт. Ощущаете торжество момента? Его величие? И силу? Нет? И верно. Ведь работа только началась! Впереди у вас — кластеризация ключевых запросов.
Вы думали, что самый длительный этап подошел к концу? Нет, это словно разминка перед марш-броском для атлета и не более.

Надеюсь, вы воспользовались советом по сбору ключевых слов под конкретные страницы и догадались их как-то разграничить в таблице. Создавая новые листы или размещая в соседних колонках, а НЕ ВСЕ В ОДНУ!
Сразу скажу о сервисах, чтобы снять этот вопрос и не возвращаться к нему. Вариантов, когда вы взяли, и скопом закинули свое семантическое ядро куда-то и оттуда получили удобную, точную кластеризацию поисковых запросов — нет. (Хотя я не исключаю, что мне просто попадались плохие сервисы анализа запросов).
Как итог: сидишь и пересматриваешь насколько качественно были сгруппированы ключевики. Несколько часов вычитываешь, пока перед глазами уже не плывут строки. Ладно, если там до тысячи запросов. А если их 100к?
Но факт остается фактом и кластеризацию проводить необходимо. Так как запросы с общими словами (перевертыши) или относящиеся к одной группе (синонимы) необходимо сгруппировать для дальнейшей работы с ними.
Вот ссылка на удобный файл для работы с семантическим ядром.
Идея была очень проста: уменьшить время и затраты на кластеризацию ключевых запросов. На помощь пришли регулярные выражения. Словно манна небесная они сошли и обрушились тяжким камнем на мою голову. Но что делать, пришлось разбираться.
Приступим к кластеризации поисковых запросов из файла.
Первым делом перенесите фразы на лист «Ключи».
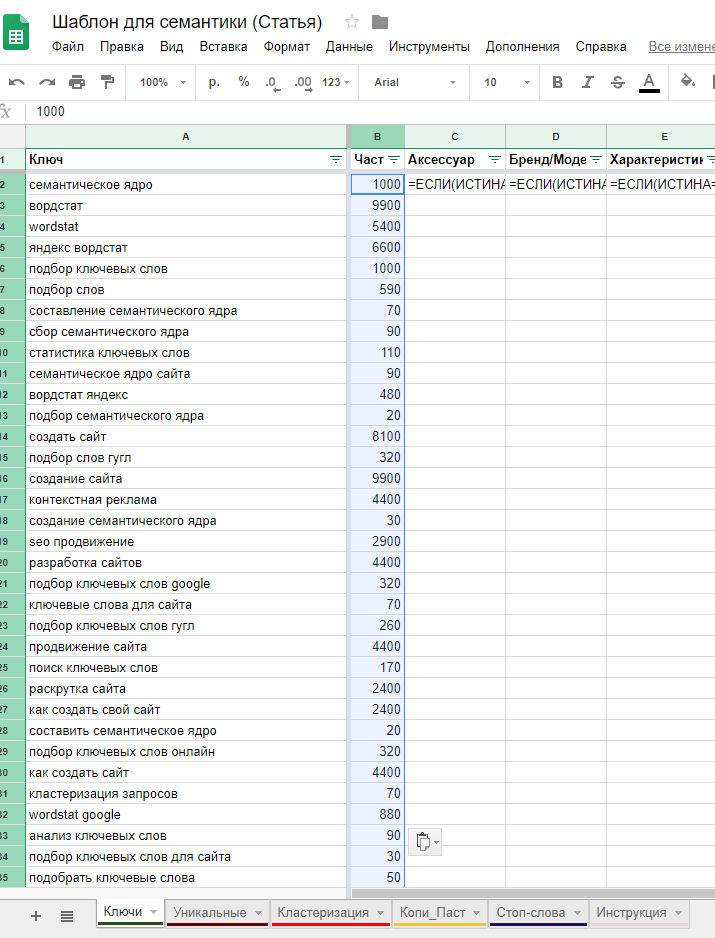
Далее, составьте список всех уникальных слов в семантике. Это удобно делать через программу Notepad++. Находите ее в поиске, скачиваете, устанавливаете, открываете. Копируете ключевики в программу, и нажимаете сочетание клавиш Ctrl+F.
Переключаетесь на вкладку «Заменить». В поле «Найти» вставляете пробел (клацаете мышкой и один раз нажимаете на эту длинную клавишу на клавиатуре).
В поле «Заменить на”» вписываете два символа “\n”. Отмечаете точкой в «Режим поиска» напротив «Расширенный».
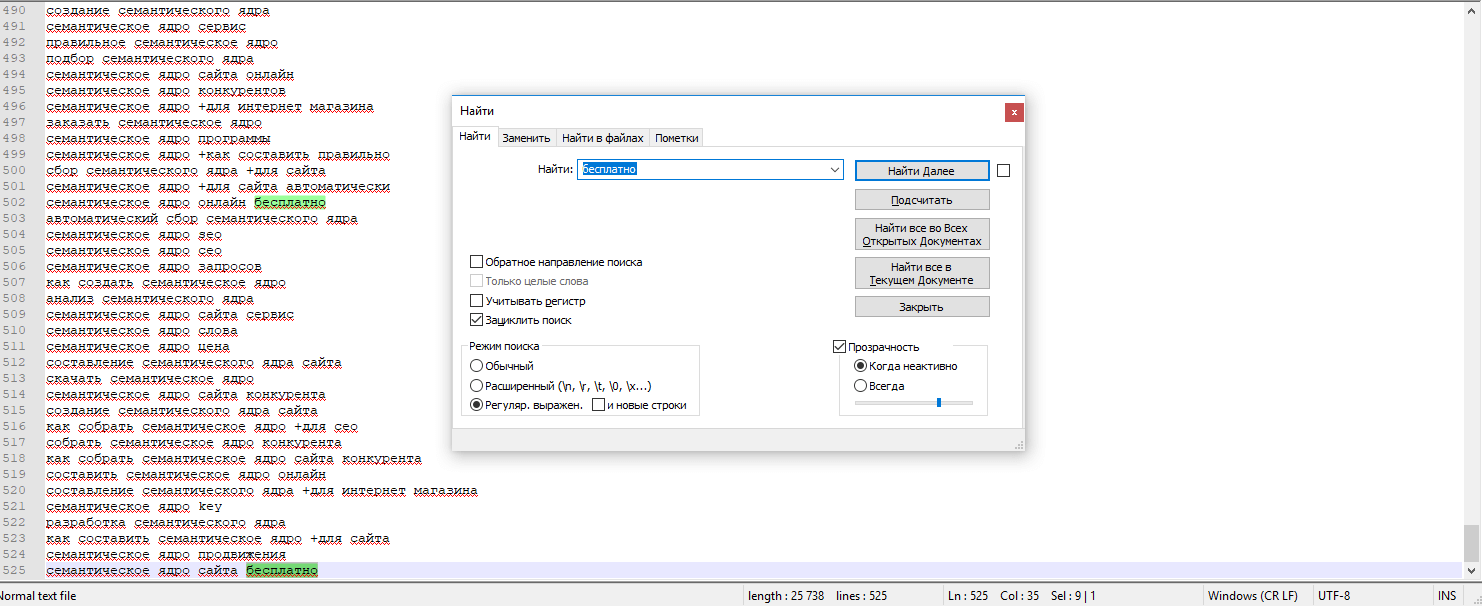
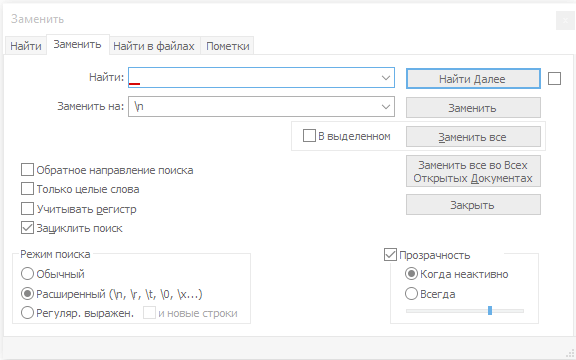
После жмете на кнопку «Заменить все» и получаете результат.
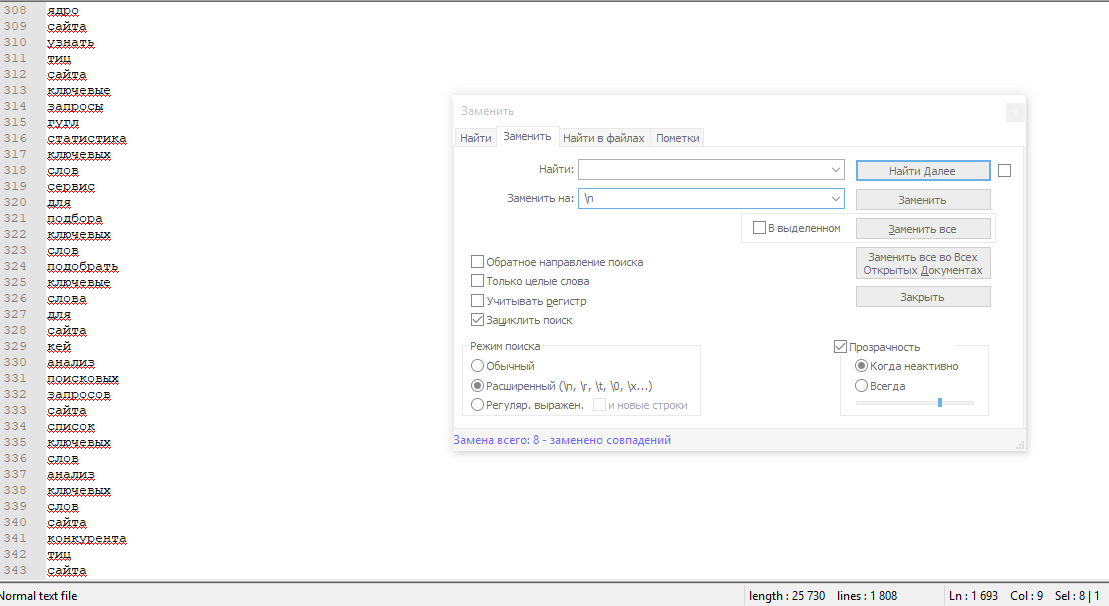
Копируете этот огромный список слов и возвращаетесь обратно в файл анализа запросов.
Переходите на лист «Уникальные» и вставляете в колонку А (начиная со второй ячейки) список слов. В колонке В будет автоматически создан список уникальных слов.
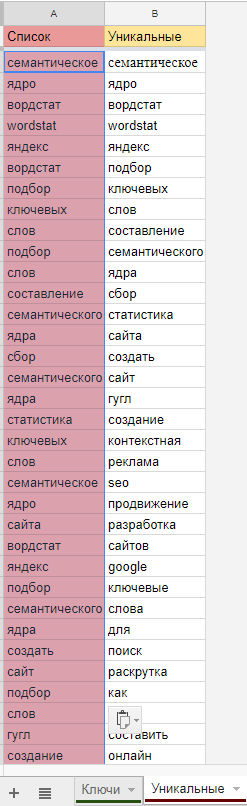
Обращаю ваше внимание, что список уникальных слов состоит всего из 261 слова, а список всех ключей насчитывает 525 запросов. В итоге вы сократили время для работы вдвое, проделав эти несложные манипуляции.
При анализе запросов очень важно убрать из списка уникальных слов цифры!
Далее, копируете список ваших уникальных слов и переходите на лист «Кластеризация». Список вставляете в колонку А, начиная со второй ячейки.
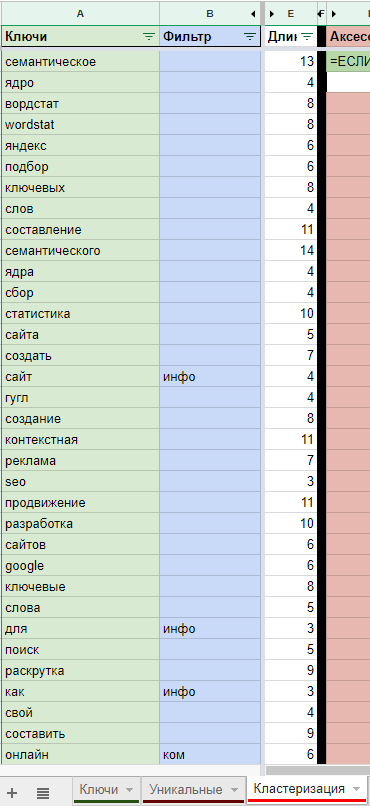
Пятиминутка в логике работы. В колонке А собраны слова, которые seo-специалисты, относят к какому-то фильтру. Фильтров можно сделать столько, сколько необходимо. Сама таблица является масштабируемой, главное, не забывать протягивать формулы.
В этом примере используются общие фильтры. «Инфо» означает, что слово относиться к информационным запросам. «Ком» к коммерческим и т. д.
Чем больше ваше СЯ и чем детальнее вы хотите его проработать, тем больше фильтров можно придумать. Ими могут быть конкретные бренды, страны, регионы, характеристики товаров или услуг. Благодаря этому, будет очень удобно фильтровать семантическое ядро по нужным параметрам. Символом “*” отмечены пустые заготовки под возможные фильтры.
Отмечая нужное слово соответствующим ему фильтром, вы автоматически добавляете это слово в фильтр, по которому далее будет происходить группировка.
Существует прямая связь между названием фильтра (название записаны в красных ячейках первой строки) и пометкой к колонке «Фильтр». Причем регистр не важен, важно само название. «Инфо» соответствует «инфо», «Инфо», «ИНФО». Но не соответствует «инф», «Инфа» и т. д. Соблюдайте ее и ошибок не будет.
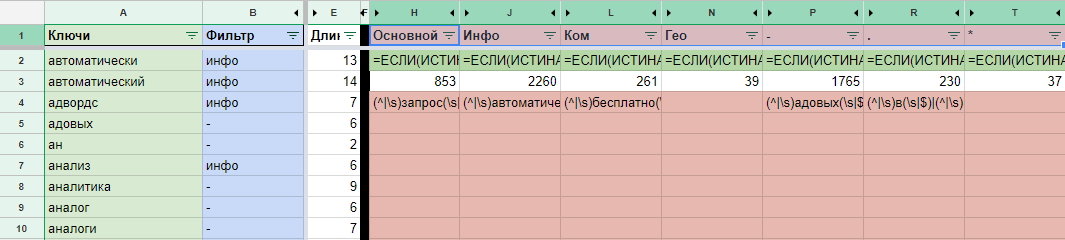
Обратите внимание, что при первом добавлении уникальных ключей, части слов автоматически присвоено значение в столбце «Фильтр». Эта информация подтягивается со страницы «Стоп-слова», но о ней позже. Остается поставить метки напротив не отмеченных слов. Отметки должны совпадать с названием фильтра.
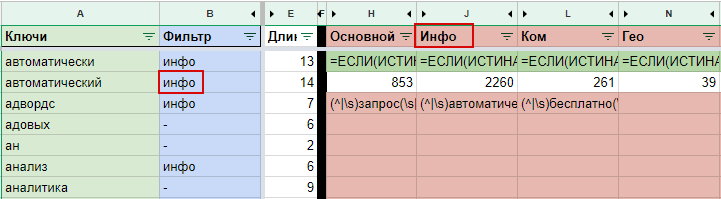
Фильтры можно переименовывать как вам удобно и добавлять новые.
На это уйдет какое-то время. Для простановки отметок напротив всех уникальных слов мне понадобилось около 10 минут. В итоге получилось так:
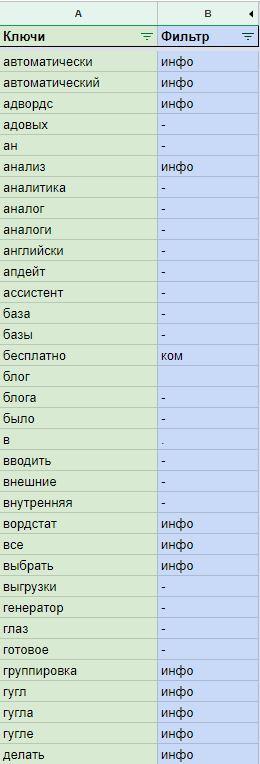
Прочерками отмечены слова, которые, на мой взгляд, являются лишними в данной семантике. При желании их так же можно разделить и вынести в свои фильтры. Важно всегда думать и иметь перед собой некую картинку, чтобы осознанно распределять слова, иначе вы рискуете потерять важные ключевые запросы.
До завершения кластеризации осталось всего пара шагов. Вернитесь на лист «Ключи». Выделите мышкой ячейки и колонки с вашими фильтрами.

После выделения нажмите сочетание клавиш Ctrl+С и тут же Ctrl+Shift+V. Пустые фильтры можете удалить, оставить или добавить потом.
И далее, вы сможете увидеть такую картину.

Не работает! :)
Формулы остались на месте, в виде текста, но не считают. Да, есть маленький нюанс. Необходимо в каждой формуле убрать символ “|” (вертикальная черта). Находится он в конце каждой из формул, перед предпоследними круглыми скобками.
Признаком того, что все сделано правильно станут ячейки с названием фильтра или пустые ячейки.

Протяните формулы на все ваши ключевые запросы и подождите какое-то время. У меня пересчет формул занял менее минуты. Вот результат:
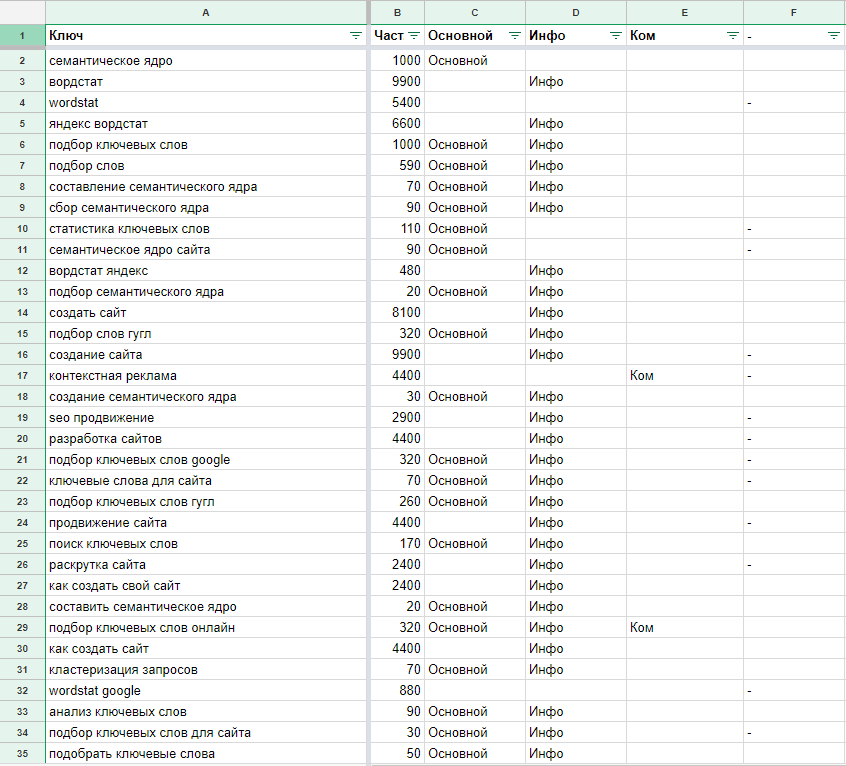
При помощи фильтров я убрал все ненужные мне фразы, в которых содержались слова, связанные с фильтрами (инфо, ком, -, .(точка)).
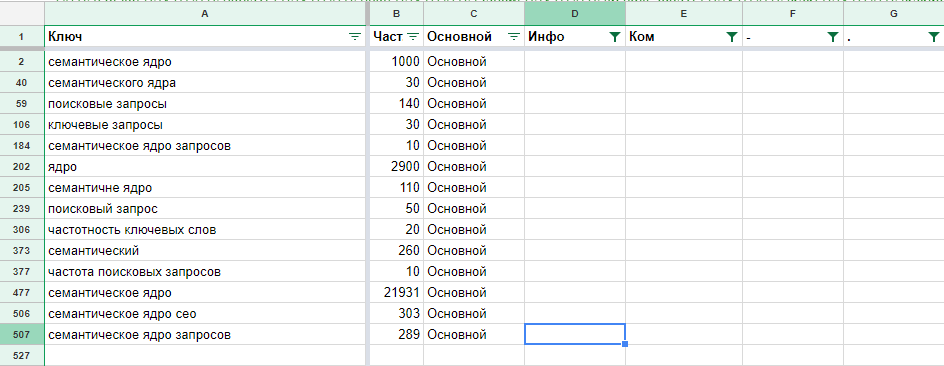
Дальнейшая манипуляция с фильтрами зависит от того, для каких целей было собрано семантическое ядро. Если вам нужны информационные запросы, связанные с основным ключом, включайте фильтр «Инфо». Если вы желаете предложить свои услуги по сбору семантического ядра за денежное вознаграждение, включайте фильтр «Ком».
Возможно, возникнет вопрос о целесообразности всех этих манипуляций, ведь можно просто в таблице как-то помечать ключевые запросы, переносить общие на другие листы и т. д. Да, можно и так. Но если посчитать все время на кластеризацию семантического ядра, то вы поймете в чем плюсы моего способа. На подготовку уникальных слов для вычитки уходит менее минуты (перенести все собранные ключевые фразы + выделить уникальные и записать их на лист «Кластеризация») + время на вычитку и расстановку меток (на 259 слов ушло около 10 минут, значит, на слово уходит примерно 2,3 секунды) + время на протягивание и пересчет формул около часа (все зависит от размера семантики, но это час, который вы можете потратить на другие дела!).
Решение о том, нужно оно или нет, принимайте сами. Краткая инструкция присутствует в файле на соответствующем листе.
Стоп-слова
Ключевую роль в работе с таблицей по кластеризации играет лист «Стоп-слова». На нем собраны запросы, которые в 99% случаях можно отнести к одной и той же категории. Например, слово «купить» будет в 99% случаях отнесено к коммерческим словам. А слово «Киев» к географическим словам и т. д.
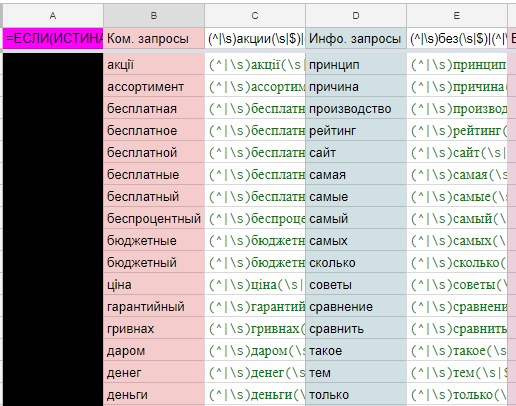
Собрав максимально полный перечень стоп-слов различного характера, можно еще больше сократить время на вычитку уникальных слов на листе «Кластеризация». Связано это с тем, что после добавления списка уникальных слов таблица автоматически проверяет их на соответствие стоп-словам. Если соответствие найдено, ставится отметка.
Вы можете удалять, менять и добавлять свои списки стоп-слов. Но придется разобраться в том, как все работает. Особенно, как все группируется в формуле ячейки А1. Сложного там ничего нет, однако, разбор формул Гугл таблиц не является темой данной статьи.
Необходимо запомнить следующее. При добавлении или удалении слова в любом из списков придется скопировать формулу из ячейки А1 и вставить ее на лист «Кластеризация» в ячейку В2. Далее, протянуть, чтобы произошла замена старых формул на новые.
Будет разумным провести работу над списком стоп-слов, а уже после этого заниматься кластеризацией поисковых запросов.
Внедрение семантики на сайт
Качественно проделав работу по сбору ключевых слов и кластеризации, вы можете внедрять семантику на сайт. Причем четко будет видно (по частотности), какие ключи могут привести больше посетителей, а какие меньше. Помните: если у вас есть ключевой запрос «купить телефон» с частотностью 20к в месяц, это не значит, что использовав его в мета-тегах, контенте, вы сможете получить такой трафик на эту страницу.
Проанализируйте свой CTR по страницам и выведите средний показатель. Например, он будет 3,5%. Получаете 700. Очень усредненное значение. Но со статистикой в нашем деле всегда так. Все очень среднее и приблизительное.
Ключевые слова следует использовать в названии страницы, мета-тегах, контенте. Вы должны дать понять поисковой системе суть той или иной страницы посредством ключевых слов на ней. Но «що занадто, то не здраво». Так что не перестарайтесь внедрением.
Что касается идеала... Так вот, идеала нет и никогда не будет. Идеал — неуловимая штука, которая будет все время меняться. А потому собрать «идеальное СЯ» невозможно.
В целом определение семантики — это процесс развития и продвижения интернет-ресурса. Точка. Мысль закончена. Не похоже, да? Но это так. Ключевое слово — процесс. И он длится до тех пор, пока вы заинтересованы в развитии своего сайта.
Машина ведь тоже не строится один раз на всю жизнь. Ее необходимо обслуживать. Проводить регулярные ТО, замену деталей, масел. Семантическое ядро необходимо периодически обновлять, внедрять новое, убирать старое и т. д.
Это была не совсем обычная и нудная статья о том, где и какие кнопки нажать, чтобы победить... коих вагон и маленький паровоз.
Ставьте лайки и дизлайки. Помните, что любая реакция — это уже победа… хотя бы наполовину.
Удачи при сборе семантического ядра своей мечты!

















Авторизуйтесь, чтобы оставлять комментарии
Oleksandr Kachkov
14.03.2019
Почему не делать все тоже самое в KeyCollector? Там тоже делаете сколько угодно списков стоп слов. И дальше разбиваете семантику. Без возни с формулами и т.п.
Валерий Сыщук
24.03.2019
Там надо 50 баксов на лицензию потратиться