
Багато хто знайомий з висловом: «Все, що потрапляє в інтернет, залишається там назавжди». Це частково завдяки вебархіву (web.archive.org). Це віртуальне сховище зберігає інформацію, яка колись була доступна в мережі. Wayback Machine «запам’ятовує» всі версії сайтів з моменту їх створення, якщо вебмайстер не встановив спеціальну заборону на збереження даних.
У цій статті ми розглянемо можливості віртуального архіву та як ефективно їх використовувати для вашого вебсайту.

Що таке вебархів і як він функціонує?
Вебархів — це сервіс, що збирає та зберігає копії сайтів. Його часто називають машиною часу, яка дозволяє «повернутися в минуле» і побачити, як виглядали сайти 5, 10 або навіть 20 років тому. Web.archive.org є некомерційною загальнодоступною цифровою бібліотекою, заснованою у 1996 році. Місія проєкту полягає у забезпеченні «загального доступу до всіх знань». Архів містить інформацію про більш ніж:
- 525 мільярдів сторінок;
- 28 мільйонів книг;
- 14 мільйонів аудіозаписів;
- 6 мільйонів відео.
Користувачі можуть ввести URL-адресу для перегляду попередніх версій будь-якого сайту, що міститься в архіві, і взаємодіяти з ними, навіть якщо цей ресурс вже не існує в «живій» мережі. Завдяки Wayback Machine можна переглядати скриншоти сайтів, які сервіс створює з певною періодичністю.
Практичне застосування вебархіву
Вебархів надає користувачам можливість:
- відновити свій сайт у разі його зламу або втрати;
- переглядати контент чи застарілу інформацію, яка вже видалена з сайту;
- аналізувати зміни обраного ресурсу за певний період;
- знаходити унікальну інформацію для подальшого використання.
Аналіз попередніх версій сторінок/сайту
Завдяки вебархіву ви можете аналізувати зміни обраного ресурсу протягом певного періоду часу. Щоб переглянути старі версії сайту, відвідайте web.archive.org і введіть адресу домену.
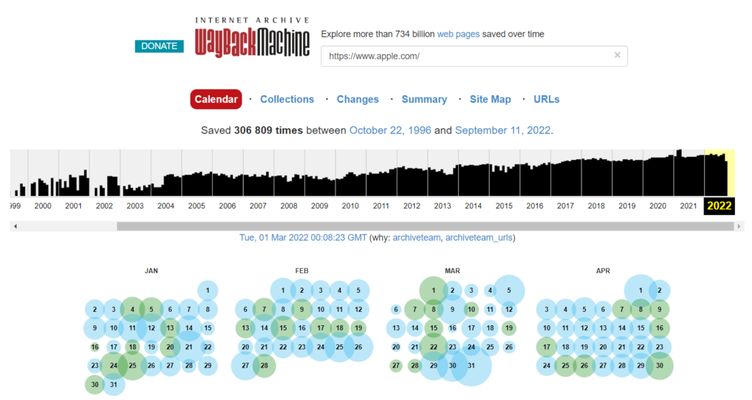
На екрані з'явиться часовий відрізок, що охоплює період з моменту заснування сайту до поточного часу. Натисніть на рік і оберіть бажану дату. Після вибору дати клацніть на неї, і Wayback Machine перенесе вас на відповідну версію сайту.
Пошук унікального контенту
Якщо сайт було видалено, пошукові системи через деякий час припиняють його індексацію. Це означає, що раніше опублікований текст стає унікальним. Такий контент можна додати на свій сайт, не турбуючись про можливі санкції від пошукових систем. Основний критерій для них — це унікальність контенту на даний момент. Таким чином, Web Archive дозволяє заощадити час і гроші на створення нового контенту. Для цього потрібно знайти список доменів, які нещодавно звільнилися. Перед тим як додати текст на сайт, перевірте його на унікальність за допомогою відповідних сервісів.
Відновлення сайту
Якщо ваш сайт з якихось причин перестав працювати, ви можете спробувати відновити його за допомогою вебархіву. Відновлювати кожну HTML-сторінку окремо може бути тривалою і складною задачею. Для цього скористайтеся спеціальними сервісами для парсингу Wayback Machine, наприклад, Archivarix.
Аналіз історії домену перед покупкою
Вебархів допоможе проаналізувати попередній вміст та тематику домену, а також побачити, як вони змінювалися з часом. Завдяки Wayback Machine ви зможете мінімізувати ризик покупки домену з поганою репутацією.
Інструменти вебархіву
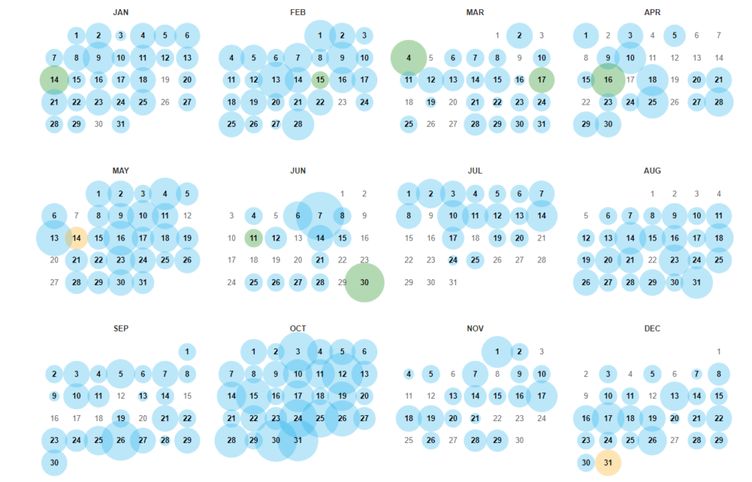
Як орієнтуватися в календарі Коли ви введете сайт для аналізу, вебархів запропонує вибрати дату в календарі. У ньому ви побачите позначки різного кольору за датами збереження:
- помаранчевий — помилка клієнта;
- червоний — помилка сервера;
- синій — позитивна відповідь сервера;
- зелений — редирект.
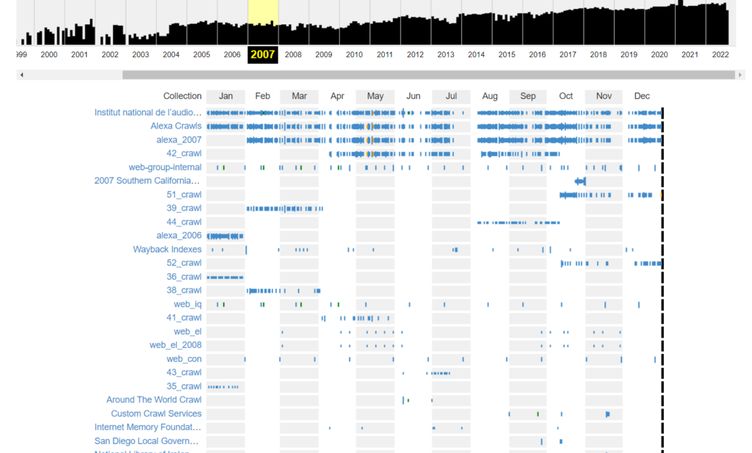
Інструмент «Колекції»
Колекції — це групи сканувань, які мають різні цілі або спрямовані на певні групи доменів, такі як TLD-домени, сторінки з непрацюючими посиланнями чи регіональні сайти. Завдяки цьому інструменту можна дізнатися причину архівації конкретної URL-адреси. Для цього необхідно клікнути по колекції, після чого відобразиться додаткова інформація про неї.
Інструмент «Зміни»
Цей інструмент Wayback Machine дозволяє порівняти дві версії сайту. Для цього перейдіть до розділу «Changes», і вебархів завантажить усі знімки, розділені за роками.
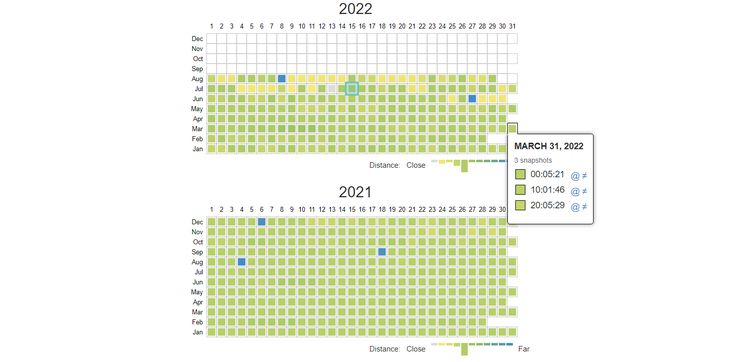
Зі спливаючого списку виберіть два знімки сайту, далі натисніть кнопку порівняння. Наприклад, можна зіставити версії сайту за 3 роки.
Інструмент «Зведення»
Цей інструмент дозволяє переглянути статистику архіву. Вибравши потрібний інтервал часу, ви побачите всі графіки і таблиці. Наприклад, стовпець New URLs показує кількість нових унікальних URL-адрес, що додані в архів за вказаний період.
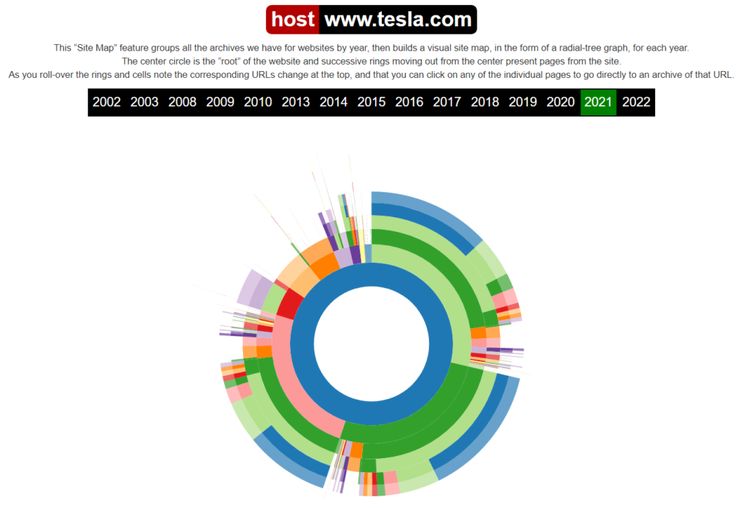
Інструмент «Карта сайту»
Для кожного року Wayback Machine надає візуальну карту сайту у вигляді діаграми. Центральне коло представляє «корінь» сайту, а кільця навколо нього — сторінки сайту. Щоб перейти до архіву потрібної URL-адреси, просто клацніть на будь-яку з окремих сторінок.
Як зберегти поточну версію сайту у вебархіві
Копії сайтів потрапляють до Web Archive після сканування вебкраулером, але ви також можете зробити це самостійно. Для цього на головній сторінці Wayback Machine знайдіть опцію «Save page now'», введіть URL-адресу і натисніть «Save Page». Цю дію рекомендується виконувати перед важливими змінами на сайті і після них. У разі втрати даних або краху, ви зможете відновити веб-сторінку.
Як заборонити додавання сайту до веб-архіву?
Щоб заборонити додавання вашого сайту до Web Archive, встановіть файл robots.txt або мета-тег noarchive. Ці заходи запобігають індексації вашого контенту вебкраулером. Переконайтеся, що вони правильно налаштовані перед початком роботи над сайтом.
Заборона додавання вашого сайту до Wayback Machine є важливою для збереження унікальності контенту після видалення сайту, майбутнього продажу доменного імені без зв'язку з попереднім вмістом чи для захисту особистої інформації від публічного доступу. Існує кілька способів цього досягнути на web.archive.org.
Звернення в підтримку Wayback Machine Якщо ви хочете видалити наявну інформацію про свій сайт з архіву та перестати його сканувати в майбутньому, зверніться в підтримку Wayback Machine. Для цього напишіть листа на info@archive.org і вкажіть доменне ім'я у тексті повідомлення. Після обробки запиту інформація буде видалена, а краулери припинять сканувати ваш сайт.
Використання файлу robots.txt За допомогою файлу robots.txt можна заборонити доступ вебкраулерам до вашого сайту. Це призведе до припинення сканування інформації та її додавання до архіву Wayback Machine. Важливо зауважити, що вже проскановані дані залишаться у архіві і будуть доступні для перегляду користувачам.
Для того щоб заборонити доступ, вам необхідно додати наступні директиви до файлу robots.txt у кореневому каталозі вашого сайту:
User-agent: ia_archiver Disallow: /
User-agent: ia_archiver-web.archive.org Disallow: /
Це призведе до того, що вебкраулери не будуть відвідувати ваш сайт. Крім цього, сайти, захищені паролем, також не скануються вебкраулерами.
Як відновити сайт із вебархіву?
Відновлення контенту із Wayback Machine може бути необхідним у випадку втрати або зламу сайту, коли резервних копій немає. Існують різні способи відновлення за допомогою цього інструменту.
Вручну копіювати контент Wayback Machine не надає автоматизованого засобу для відновлення всього сайту, але ви можете вручну скопіювати текст, код сторінок та зображення. Для цього перейдіть на сторінку вебархіву, клацніть правою кнопкою миші і виберіть 'View page source'. Скопіюйте HTML-код сторінки і вставте його в текстовий редактор, де зможете зберегти як HTML-файл.
Скопіювати контент за допомогою скриптів Для спрощення процесу відновлення можна використовувати спеціальні скрипти, які дозволяють автоматично отримувати весь контент сайту з архіву. Наприклад, ви можете скористатися такими інструментами, як Wayback Machine Scraper, Wayback Scraper або Hartator Wayback Machine Downloader (Ruby).
Відновлення сайту за допомогою сторонніх сервісів Існують також сторонні сервіси, які спеціалізуються на відновленні веб-сайтів із вебархіву. Вони пропонують різні сервіси і вартість залежить від обсягу роботи. Деякі з найбільш відомих сервісів включають:
- Archivarix.
- Web Archive Org.
- Rush Analytics.
- Wayback Machine Downloader.
Вибір методу відновлення залежить від вашого конкретного випадку: вручну копіювати кілька сторінок, скористатися скриптами для автоматизації або звернутися до професійного сервісу для відновлення всього сайту.
Хочете стати SEO-спеціалістом?
Якщо ви хочете навчитися оптимізувати сайти і стати суперменом-сеошником, ми можемо запропонувати курс SEO-спеціаліст. В процесі навчання ви проведете аудит сайту і створите стратегію просування. Також навчитесь аналізувати конкурентів і сформуєте семантичне ядро. А, прогнозуючи результати просування, зможете оптимізувати бюджет. Привабливо? Записуйтесь!
Детальніше про курсРезюмуємо
Вебархів (web.archive.org) — це цифровий архів усього інтернету. Ресурс зберігає в собі всі версії сайту з моменту їх створення, якщо власник не встановив заборону на збереження інформації.
За допомогою Wayback Machine можна проаналізувати попередні версії сторінок або сайту, знайти унікальний контент, відновити сайт, переглянути історію домену перед купівлею.
Закрити доступ вебархіву до сайту можна за допомогою файлу robots.txt або звернутися в підтримку.
Відновити сайт за допомогою web.archive.org можна в кілька способів: скопіювати контент вручну, за допомогою скрипта або скористатися сторонніми сервісами.



















Авторизуйтесь , щоб залишати коментарі